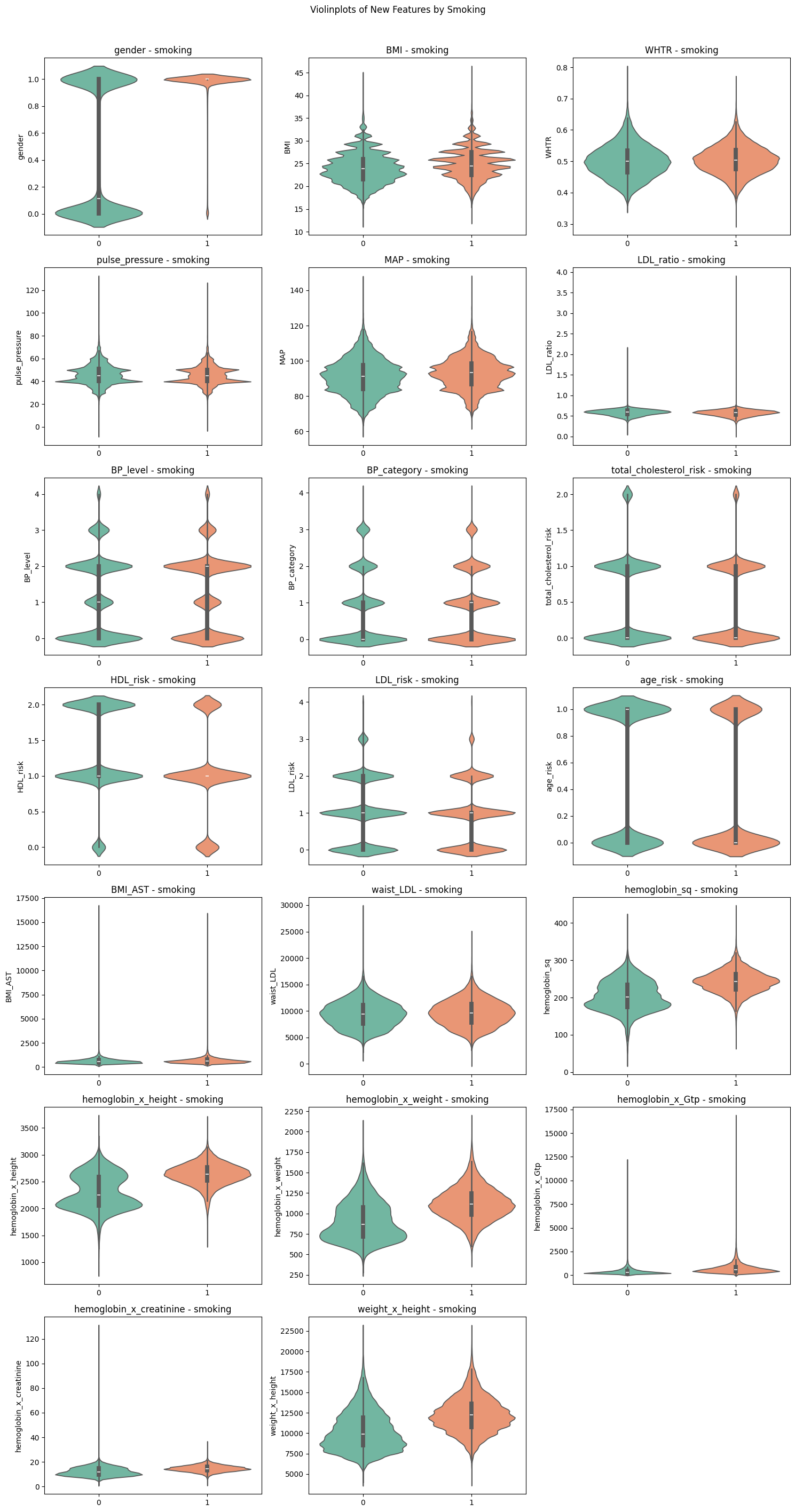
왜 벌써 회고를?이번 DATAThon 프로젝트에서는 팀원들과 함께 3일간(+⍺ 조금..?) 한 개의 데이터셋을 가지고 흡연 여부를 예측하는 모델을 만들었다.EDA와 파생 변수 생성은 내가 직접 진행한 부분이었고, 그 이후의 모델링 과정은 다른 팀원들이 중심이 되어 작업해 주셨다.Feature Engineering까지 작업한 후에는 발표자료를 만드는 작업을 했고, 최종 모델 선정과 결과는 팀원들이 도출해 주셨다. 그래서 모델링 과정은 생략한 채, 간단히 결과를 요약하고이 프로젝트를 통해 얻은 인사이트와 느낀 점들을 중심으로 회고를 남겨보려 한다. 최종 모델과 전략 요약우리 팀의 최종 모델은 LightGBM, XGBoost, CatBoost를 활용한 Soft Voting 앙상블 모델이었다.최종 ROC-AUC..